Scala Floor A Spark Column

Trim Lighting Floors Love The Stain And White Combination Like The Column With The Staircase Stairs Design Interior House Staircase Design

Boston Property Log In Home Classic Interior Interior

Dataframe With Dynamic When Condition Using With Column Stack Overflow

2019 Codaawards Highlight The Best Site Specific Artwork Hotel Lobby Design Lobby Design Lobby Interior Design

Gallery Of Ih Residence Andramatin 10 Dutch Colonial Homes Corridor Design Tropical Architecture

Painted Column Ideas Column And The Ceiling Panels Were Painted In Different Shade Minimalist Interior Design Interior Design School Minimalist Interior
Val people sqlcontext read parquet in scala dataframe people sqlcontext read parquet in java.
Scala floor a spark column.

Reality And Misconceptions About Big Data Analytics Data Lakes And The Future Of Ai In 2020 Big Data Big Data Analytics Business Intelligence

Ancient Live Edge Dining Table Live Edge Dining Table Live Edge Table Live Edge Design

Replace Roman Columns With Base Cabinets And Craftsman Style Beams House House Design Home
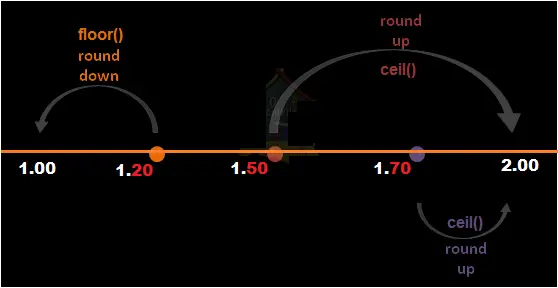
Round Up Round Down And Round Off In Pyspark Ceil Floor Pyspark Datascience Made Simple
Source : pinterest.com
